Jeudi 24 Juillet 2025
Le 21 juillet, Alibaba a rendu public sur X la récente actualisation de son LLM Qwen 3 : Qwen3-235B-A22B-Instruct-2507. Ce modèle open source, diffusé sous licence Apache 2.0, dispose de 235 milliards de paramètres et ambitionne de rivaliser sérieusement avec DeepSeek‑V3, Claude Opus 4 d'Anthropic, GPT-4o d'OpenAI, ou encore Kimi 2, récemment lancé par la jeune entreprise chinoise Moonshot et quatre fois plus volumineux.
Alibaba Cloud précise dans sa publication :
"Après concertation avec la communauté et mûre réflexion, nous avons opté pour l'abandon de l'approche hybride. Désormais, nous allons entraîner les modèles Instruct et Thinking de manière distincte afin d'obtenir une qualité optimale".
Qwen3-235B-A22B-Instruct-2507 est un modèle dit "non-réfléchi", c’est-à-dire qu'il ne procède pas à un raisonnement en chaîne complexe, mais favorise la vélocité et la justesse dans l'exécution des instructions.
Grâce à cette orientation stratégique, Qwen 3 ne se contente pas de progresser dans l'exécution des instructions, mais démontre également des améliorations en matière de raisonnement logique, de compréhension pointue de domaines spécialisés, de traitement des langues moins courantes, ainsi que dans les domaines des mathématiques, des sciences, de la programmation et de l'interaction avec les outils numériques.
Dans les tâches ouvertes, sollicitant le jugement, la tonalité ou la créativité, il s'adapte plus finement aux attentes des utilisateurs, en proposant des réponses plus pertinentes et un style de génération plus naturel.
Sa fenêtre contextuelle, étendue à 256 000 tokens, a été multipliée par huit, lui permettant ainsi de traiter des documents de grande taille.
Une architecture axée sur la flexibilité et l'efficacité
Le modèle repose sur une architecture Mixture-of-Experts (MoE) comprenant 128 experts spécialisés, dont 8 sont sélectionnés en fonction de la requête : sur ses 235 milliards de paramètres, seuls 22 milliards sont activés par demande.
Il s'appuie sur 94 couches de profondeur, un schéma GQA (Grouped Query Attention) optimisé : 64 têtes pour la requête (Q) et 4 pour les clés/valeurs.
Performances de Qwen3‑235B‑A22B‑Instruct‑2507
La nouvelle version affiche des résultats compétitifs, voire supérieurs, à ceux des modèles des principaux concurrents, notamment en mathématiques, en codage et en raisonnement logique.
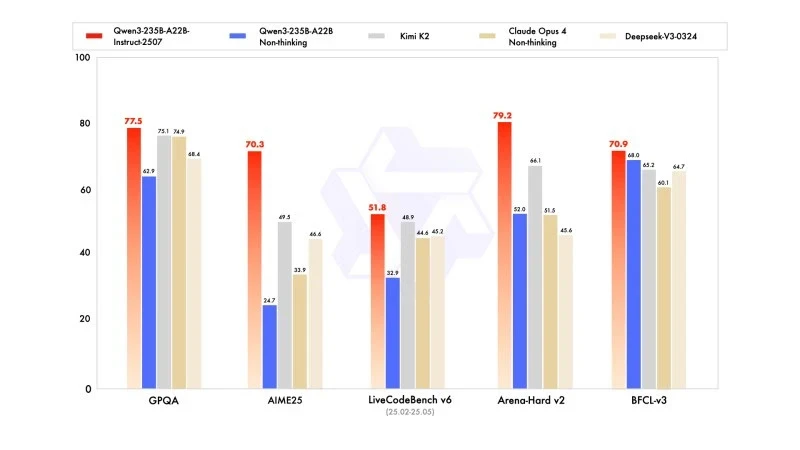
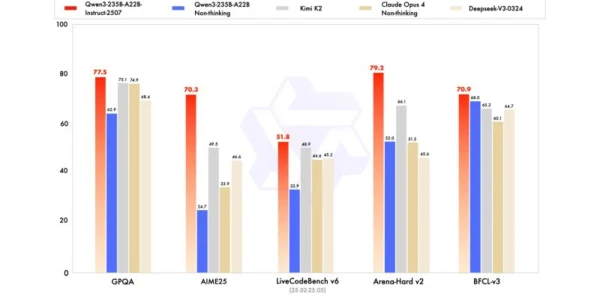
En connaissances générales, il a obtenu un score de 83,0 sur MMLU-Pro (contre 75,2 pour la version précédente) et 93,1 sur MMLU-Redux, se rapprochant du niveau de Claude Opus 4 (94,2).
En raisonnement avancé, il a atteint un score très élevé dans la modélisation mathématique : 70,3 sur AIME (American Invitational Mathematics Examination) 2025, surpassant les scores de 46,6 de DeepSeek-V3-0324 et de 26,7 de GPT-4o-0327 d’OpenAI.
En codage, son score de 87,9 sur MultiPL‑E, le place derrière Claude (88,5), mais devant GPT-4o et DeepSeek. Sur LiveCodeBench v6, il atteint 51,8, ce qui représente la meilleure performance mesurée sur ce benchmark.
Version quantifiée en FP8 : optimisation sans compromis
Simultanément à Qwen3-235B-A22B-Instruct-2507, Alibaba a mis à disposition sa version quantifiée en FP8. Ce format numérique compressé diminue considérablement les besoins en mémoire et accélère l'inférence, permettant ainsi au modèle de fonctionner dans des environnements aux ressources limitées, et ce, sans induire de perte significative de performance.





